Amazon Rekognition offers image and video analysis capabilities, with a range of out-of-the-box capabilities like facial analysis, facial identification, and object identification. Amazon Rekognition Custom Labels allows you to take Rekognition's ability to identify images and build machine learning models on collections of images.
Getting Started
From the AWS Console, navigate to Amazon Rekognition, and select "Use Custom Labels" from the left menu. From the left menu of the Amazon Rekognition Custom Labels page, select "Projects". If you haven't yet created any projects, you will first be prompted to allow Rekognition to create an S3 bucket. Click "Create S3 Bucket". This will create a bucket in your currently selected region.
Create a Project
The first step is to create a new project, which is done by clicking "Create project" (these are the brilliant insights you come here for). All you need for a project is a name, so it's pretty simple.
Add a Dataset
The project needs a dataset, so the first task will be to "Create dataset". There are two options for creating a dataset: the simplest option is to use a single dataset (the default choice). If you do this, Rekognition will automatically split the dataset into training and test subsets. Alternatively, if you already have a dataset split into training and test sets, you can select to create the dataset that way.
There are also multiple options for where to load your data from. While you can upload them driectly from your machine, I've found this approach to be unreliable, probably because image files can be on the large side. This approach is also limited to only 30 files. There are also other benefits to loading from an S3 bucket, as we'll see later.
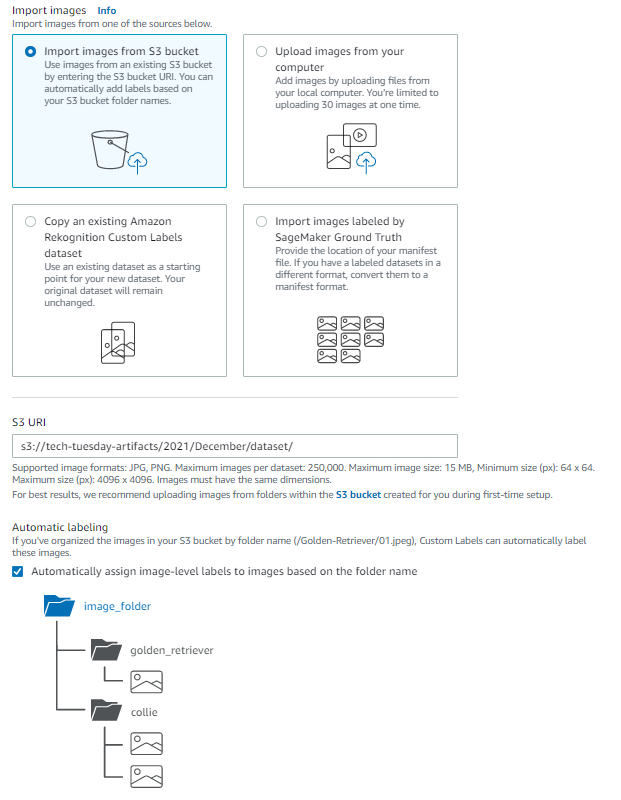
So for a new project with a new dataset, we will load images from an S3 bucket. One significant benefit to loading images this way is the option for automatic labeling. This option will use the folder structure of the S3 bucket to infer label for the image files. Ensure the S3 URI includes the apprpriate prefixes so that the labels can be identified (such as in the example below, where the files are located in a folder named "dataset"):
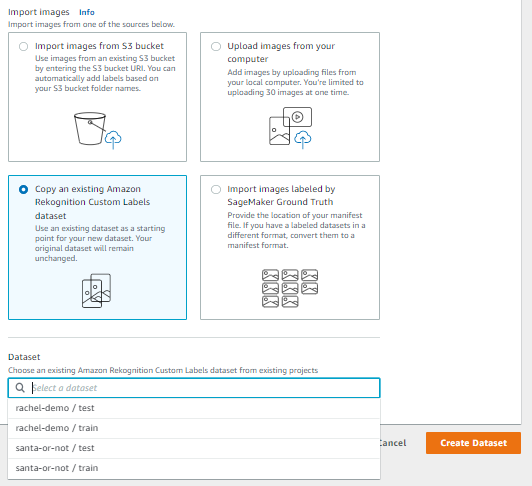
If you already have a project with a dataset (in the same account and region) and want to reuse that dataset, Rekognition also offers the option of creating a dataset using an existing dataset. When you select this option, the available datasets will be shown in a list:
Finally, you can also load datasets from SageMaker.
Labeling a Dataset
If you didn't use automatic labeling, or want to add additional labels, you can us the "Add labels" feature in the AWS Console. Once you click "Start labeling", you will have the option of assigning either image-level labels, or of selecting an area within an image to attach a label to. Ensure you click "Save changes" prior to clicking "Finish Labeling" to ensure your new labels are applied.
Training the Model
Once your project has a dataset, you can train the model. Model training can take an hour or more, depending on the number of images and labels. Once it's complete, the project will have a model listed in the "Models" pane, and it will have a status of "TRAINING_COMPLETED". You can click on the model name to see some details about the training results:

The date completed will also show how long the model took to train in hours. The model performance will be described with the F1 score, precision, and recall. These metrics are all indexed to 1, with 0 being the lowest score and 1 being the best. However, it is important to note that even high scores indicate only how well the model will perform based on images represented by the training dataset. For example, if your training dataset includes only images of tree leaves and has an F1 score of .95, it may not do a good job of identifying images of entire trees.
Using the Model
Once the model has been trained, it needs to be started before you can use the model. It may take several minutes to start the model, but once it is started it should respond quickly. A model only incurs fees during training and when running, so it's important to remember to stop your model when you are done with it so that you don't continue to incur fees.
When starting the model, you can manage the throughput level of your model by adjusting the number of "inference units" to be used. Once the model is started, you cannot increase or decrease the number of inference units without stopping and restarting the model.